Exploring Direct Policy Search via Evolutionary Algorithms (2022)
Introduction
Black Box Optimization via Evolutionary Algorithms. Evolution strategies (ES) belong to a class of nature-inspired optimization methods known as evolutionary algorithms, which were initially developed by H. Beyer in 1989. These algorithms utilize adaptation, selection, and recombination of individuals, representing potential solutions, to iteratively improve solutions. It’s crucial to emphasize that while these algorithms draw inspiration from biological evolution, their mathematical formulations are highly abstract, making it more appropriate to regard evolution strategies as a class of black-box stochastic optimization techniques designed for tackling continuous non-linear or non-convex problems.
Given a black-box function \(f: D \subset \mathbb{R}^{N_x} \rightarrow \mathbb{R}\), the focus lies on the optimization problem:
\[\boldsymbol{z}^{\star}:=\underset{\boldsymbol{z} \in \Omega}{\arg \max } f(\boldsymbol{z}),\]with \(\Omega \subset \mathbb{R}^{N_x}\). Rather than directly solving this objective, one can seek a solution to the following objective:
\[\boldsymbol{\vartheta}^{\star}:=\underset{\boldsymbol{\vartheta} \in \Omega}{\arg \max } \mathbb{E}_{p(\boldsymbol{z} \mid \boldsymbol{\vartheta})} f(\boldsymbol{z}),\]where \(p(\boldsymbol{z} \mid \boldsymbol{\vartheta})\) represents a distribution on \(D\), parameterized by the vector \(\boldsymbol{\vartheta} \in \Omega\). If \(p(\boldsymbol{z} \mid \boldsymbol{\vartheta})\) can sample points near the maximum of \(f(\boldsymbol{z})\), these two formulations yield the same solution. The stochastic formulation of the optimization problem provides a solid foundation for analyzing derivative-free algorithms and allows for the integration of auxiliary information.
The general structure of the ES algorithm follows these steps: (1) Sample Population: In each generation, the ES Algorithm samples individuals from the population based on a selected probability density function. (2) Evaluate Individuals and Update Parameters: Each individual is evaluated, and the problem parameters are subsequently adjusted to increase the likelihood of sampling individuals closer to the maximum of the chosen objective function in comparison to previous generations.
Reinforcement Learning. Reinforcement learning problems are characterized by closed-loop systems where agents learn how to map states to actions with the aim of maximizing cumulative rewards. The states represent observations obtained from the environment, while the actions are generated based on the agent’s policy, which depends on the state. Consequently, to maximize cumulative rewards during training, the learning system must strike a balance between exploration and exploitation. In policy-based reinforcement learning, the policy \(\pi_{\boldsymbol\vartheta}(\,\cdot\,|s_t)\) is parameterized by a vector \(\boldsymbol\vartheta\in\mathbb{R}^d\), determining the actions of the learning agent as a function of the states as mentioned by Recht et al. (2019).
In the realm of mathematical optimization, our goal is to solve the following problem:
\[\text{max}_{\boldsymbol\vartheta\in\mathbb{R}^d}\mathbb{E}_{a_t\sim\pi_{\boldsymbol\vartheta}(\,\cdot\,|s_t)} \left[\sum_{t=0}^{T-1}\gamma^tr(s_t,a_t)\big|s_0=s\right]\]Here, \(\gamma\) is a discounting factor, and \(r(s_t,a_t)\) represents the reward obtained in state \(s_t\) after taking action \(a_t\). Since we are primarily interested in controlling continuous locomotion tasks, \(r(s_t, a_t)\) denotes the cumulative sum of discounted returns observed by the agent.
The optimization problem outlined in in the previous equation closely resembles the problem described in the above section when considering black-box optimization.This approach is commonly referred to as direct policy search or neuro-evolution when applied to neural networks.
Contributions and Methods
In this comprehensive study, I explored two distinct methodologies aimed at addressing the aforementioned black-box optimization problem. The first approach focused on obtaining solutions through precise Maximum Likelihood (EM) and Maximum A Posteriori estimations (MAP). In contrast to the CMA-ES algorithm proposed by Hansen (2016), my approach aimed to implement algorithms that adhere closely to the theoretical foundations, without employing an evolutionary path or making modifications to the covariance matrix update, such as the “rank-\(\mu\)” update.
The second approach was grounded in a gradient-based strategy. In this approach, I developed two algorithms: Natural Gradient Descent based (NGA) and a Newton-Raphson based algorithm (SNM), taking inspiration from the work done respectively by L. Tan (2021) and Haley et al. (1984). It’s important to note that for the Natural Gradient method, I utilized normalized gradient ascent updates to ensure more stable and efficient optimization.
To maintain positive-semidefiniteness at each iteration in the gradient-based methods, I updated the Cholesky decomposition of the covariance matrix.
Taking inspiration from the seminal works of Salimans et al (2017) and Mania et al. (2018), I conducted a thorough investigation into the applicability of Evolution Strategies for direct policy search in handling continuous problems within the classical MuJoCo benchmark tasks. The selected benchmark tasks included the Inverted-pendulum, Swimmer, Hopper, Walker2D, and Half Cheetah locomotion challenges. While the Inverted-pendulum, Swimmer, and Hopper tasks had relatively low dimensionality action and observation space, I prudently imposed constraints on the covariance matrix for the Walker2D and Half Cheetah tasks to enhance computational efficiency, ensuring it remained diagonal.
For representing policies, I opted for linear policies with batch normalization. Throughout the optimization process, I employed individual selection, assigning a weight close to zero to the bottom-performing \(25\%\) of the population at each generational step. Additionally, I maintained a discount factor of \(\gamma = 1\) and limited the maximum number of steps per environment to \(T = 1000\). Subsequently, I conducted a comprehensive performance comparison of my algorithms with two established benchmarks: Trust Region Policy Optimization (TRPO) and the Evolutionary Algorithm from Salimans et al.(2017) (ES-Sal).
Results and Observations
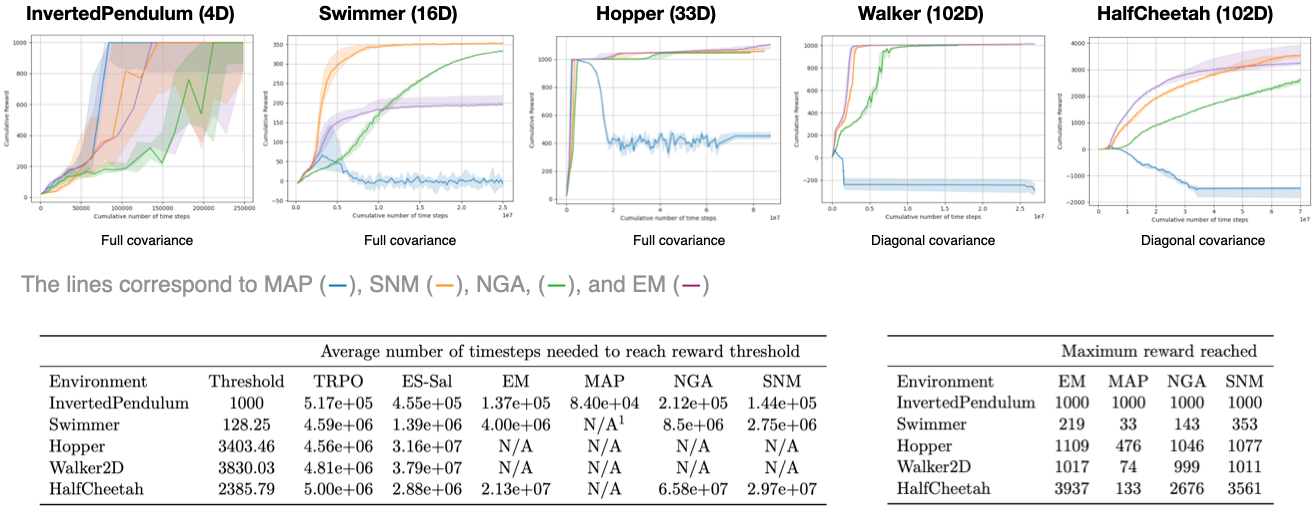
The figures above show that most of the algorithms proposed in this work are capable of training policies for simple Mujoco locomotion tasks. The results obtained also make it clear that all four algorithms outperform both the TRPO and Evolutionary Strategies (ES) algorithms in the Inverted Pendulum task. For the Swimmer task, it is evident that all algorithms are outperformed by the ES-Sal algorithm. However, the SNM and EM algorithms still outperform the TRPO algorithm. On the other hand, the other algorithms either perform worse (NGA) or fail to achieve any rewards (MAP).
In the Halfcheetah task, only the SNM, EM, and NGA algorithms managed to reach the performance threshold set by Salimans et al.(2017). Nevertheless, our algorithms required approximately ten times more cumulative time steps compared to the ES-Sal and TRPO algorithms.
For the remaining locomotion tasks (Hopper and Walker2D), all my algorithms could only reach about \(25\%\) of the predefined threshold. This inability to control these tasks can be attributed to two factors. Firstly, the linearity of the policies used was insufficient to fully capture the complex relationships between actions and states. In Salimans et al.(2017), a two-layer neural network with 64 neurons per layer was employed to establish a more intricate and nonlinear mapping between state and action. Secondly, even the use of a diagonal covariance matrix did not facilitate the learning of these intricate locomotion tasks.
Conclusion
This study aimed to develop straightforward algorithms for effective performance on common continuous control locomotion tasks in MuJoCo. While algorithms like MAP, SNM, and EM demonstrated state-of-the-art sample efficiency on certain basic benchmark control problems when employing linear policies, my findings shed light on potential limitations associated with a strictly theoretical approach in algorithm derivation. Notably, the absence of an evolutionary path, the “rank-\(\mu\)” update, and the failure to scale the gradient step, as discussed in Mania et al. (2018), can hinder algorithm convergence to a state-of-the-art level in certain scenarios. These insights underscore the importance of striking a balance between theoretical underpinnings and practical considerations when developing algorithms for reinforcement learning in complex tasks.
The code for this work is available here.